登錄


基本概括
產(chǎn)品介紹
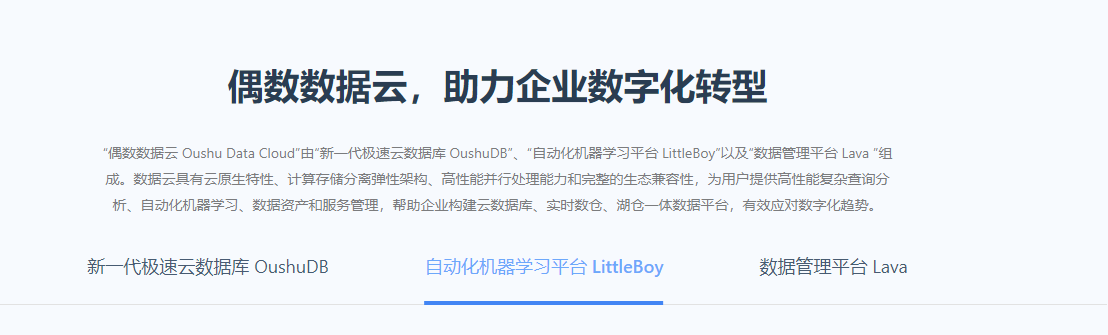
輕松構(gòu)建企業(yè)核心數(shù)倉、數(shù)據(jù)集市、實時數(shù)倉以及湖倉一體數(shù)據(jù)平臺
zData是云和恩墨自主研發(fā)的軟硬件整合的數(shù)據(jù)庫一體機產(chǎn)品
所屬公司
北京偶數(shù)科技有限公司
云和恩墨(北京)信息技術(shù)有限公司
成立時間
2016年
2011年
融資情況
B+輪
股權(quán)融資,未披露
人員規(guī)模
201-500人
501-1000人
主要客戶規(guī)模
-
大型企業(yè)(76%)
主要服務(wù)行業(yè)
-
服務(wù)(100%)
定價
免費試用
不支持
不支持
定制
不支持
不支持
價格套餐
-
獲取獨家報價
-
獲取獨家報價
客戶規(guī)模
小型企業(yè)
(50人及以下)
-
6%
中型企業(yè)
(51-1000人)
-
18%
大型企業(yè)
(1000人以上)
-
76%
客戶行業(yè)
-
服務(wù) 100%
評分
綜合評分
暫無評分

暫無評分
易用性
暫無評分
暫無評分
穩(wěn)定性
暫無評分
暫無評分
售后服務(wù)
暫無評分
暫無評分
將此報告發(fā)送至我的郵箱
發(fā)至郵箱
問答
熱門問答

客戶案例



分類
特殊分類
-
-
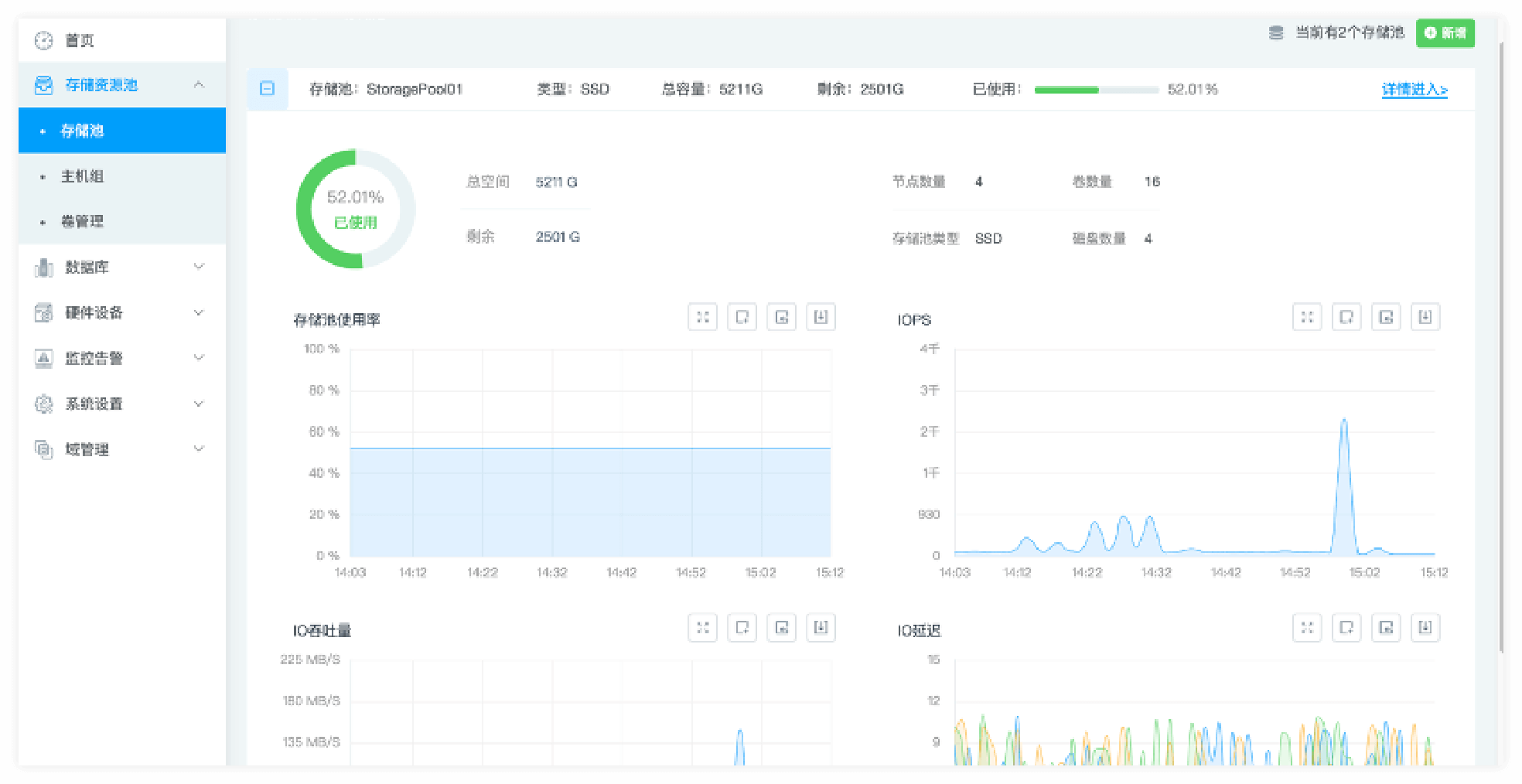
產(chǎn)品截圖
截圖對比
1/3
1/7






消息通知
咨詢?nèi)腭v

商務(wù)合作
