墨芯發(fā)布32倍稀疏AI計(jì)算卡,性能對標(biāo)英偉達(dá) | 甲子首發(fā)

搭載墨芯首款芯片ANTOUM,面向數(shù)據(jù)中心AI推理應(yīng)用。
又一家對標(biāo)英偉達(dá)的AI芯片公司發(fā)布新產(chǎn)品。
2022年3月22日,墨芯人工智能宣布即將發(fā)布兩款面向云計(jì)算市場的AI計(jì)算卡:SparseOne™? S-100和SparseMegatron™? S-300,這兩款A(yù)I計(jì)算卡均搭載墨芯首顆英騰處理器(ANTOUM),是全球首款高達(dá)32倍稀疏率的AI計(jì)算芯片。
其中SparseMegatron™? S-300對標(biāo)英偉達(dá)A10和A30(全高全長),計(jì)算標(biāo)準(zhǔn)模型ResNet50,算力超90000 FPS;SparseOne™? S-100對標(biāo)英偉達(dá)T4(半高半長),算力達(dá)31031FPS,運(yùn)行ResNet50時(shí),SparseOne™? S-100與T4相比,算力超后者的6倍,而功耗則不到后者的1/2。

截止目前,墨芯已經(jīng)完成五輪融資。最近一次融資是發(fā)生在2021年底的A輪融資,金額數(shù)億人民幣,由基石資本、大灣區(qū)共同家園發(fā)展基金領(lǐng)投,同威資本、中科華盛、及深圳天使母基金跟投。2021年初墨芯依次獲得浪潮云海基金和智慧互聯(lián)產(chǎn)業(yè)基金戰(zhàn)略投資。
借產(chǎn)品即將發(fā)布之際,「甲子光年」采訪了墨芯人工智能創(chuàng)始人兼CEO王維,和他聊聊墨芯用稀疏化算法做AI計(jì)算卡的一些思考。
墨芯人工智能所在的AI芯片市場前景廣闊。根據(jù)公開資料,2020年全球AI芯片市場規(guī)模約為101億美元,年復(fù)合增長率達(dá)52.1%。其中中國云端AI芯片市場規(guī)模為111.7億元人民幣,是AI芯片的主要細(xì)分市場。
然而近年來,芯片的算力發(fā)展逐漸跟不上算力的需求。王維告訴「甲子光年」,目前AI計(jì)算對算力的需求每3.5個(gè)月就要翻一番,與此同時(shí),根據(jù)摩爾定律算力需要每18個(gè)月左右才能翻一番。
于是,傳統(tǒng)的算力供給模式將要被打破,市場不再按照算力供給方來配套設(shè)計(jì)上層的軟件和應(yīng)用場景,而需要根據(jù)具體的應(yīng)用場景,打通算法、軟件和硬件,在立項(xiàng)之初就做一體化的設(shè)計(jì)。
業(yè)內(nèi)有人將這種模式定義為“AI芯片2.0時(shí)代”。
新的時(shí)代離不開技術(shù)的創(chuàng)新與發(fā)展。本次,墨芯發(fā)布的AI加速卡,搭載了首款芯片ANTOUM,并應(yīng)用“稀疏化計(jì)算模式”,嘗試突破算力極限。
“稀疏化計(jì)算”的原理不太復(fù)雜,是指在原有AI計(jì)算的大量矩陣運(yùn)算中,將含有0元素或無效元素的計(jì)算剔除,以加快計(jì)算速度。
比如在人臉識別的場景中,傳統(tǒng)的算法會(huì)直接計(jì)算圖片中的每一個(gè)元素與現(xiàn)有圖片模型的關(guān)聯(lián),從而得出結(jié)論。而應(yīng)用稀疏化計(jì)算,先在圖片中找出需要比對的元素,而后只需計(jì)算這些元素與現(xiàn)有圖片模型的關(guān)聯(lián)。
在王維看來,一項(xiàng)好的新技術(shù),需要有足夠的創(chuàng)新性、創(chuàng)新的可持續(xù)性和可商業(yè)化三個(gè)方面。而墨芯的“稀疏化”正是這樣的創(chuàng)新技術(shù)。
在創(chuàng)新性方面,業(yè)內(nèi)的共識是,一項(xiàng)革命性的技術(shù)需要比現(xiàn)有的技術(shù)強(qiáng)10倍以上,比如性能高10倍、功耗低10倍、或者成本降低10倍等。王維介紹,應(yīng)用稀疏化算法,能夠?yàn)榭蛻籼峁?4~32 倍稀疏化壓縮能力,計(jì)算速度能夠達(dá)到原有的10~20倍。
在可持續(xù)性方面,王維覺得,隨著AI模型參數(shù)越來越大,算力增長得越來越快,模型的稀疏性也將越高,未來的模型可以稀疏50倍甚至100倍。
在可商業(yè)化方面,墨芯做了更多前置思考。
隨著AI芯片賽道的逐漸成熟,除了技術(shù)與產(chǎn)品性能方面的競爭,“商業(yè)化落地”方面的考量變得愈發(fā)重要。
具體來說,墨芯希望通過降低客戶的TCO(單位算力的硬件擁有成本),讓客戶更愿意使用。TCO主要可以分為兩個(gè)方面,包括硬件購買成本和使用的能耗成本。
互聯(lián)網(wǎng)及科技企業(yè)對于數(shù)據(jù)中心的需求非常大,大型的互聯(lián)網(wǎng)公司每年在數(shù)據(jù)中心建設(shè)方面的投入能夠達(dá)到數(shù)十億的規(guī)模。由于墨芯的計(jì)算卡擁有目前GPU的5~10倍的等效算力,在單卡價(jià)格相當(dāng)?shù)那闆r下,可以大幅降低客戶整體的采購成本。
除此之外,客戶的使用和遷移成本也較低。墨芯開發(fā)的編譯器已適配其計(jì)算卡,支持通用的AI開發(fā)平臺TensorFlow、PyTorch或MXNet等。在具體的應(yīng)用,墨芯軟件棧Moffett NNKit 中特有的 Moffett NNCompressor 為客戶模型提供 4-32 倍稀疏化壓縮能力,客戶依舊可以在熟悉的TensorFlow或PyTorch環(huán)境里進(jìn)行開發(fā),方便遷移與交付。
在使用成本方面,墨芯更關(guān)注能效比。王維介紹,相較于市場旗艦產(chǎn)品,S-100運(yùn)行ResNet 50時(shí),每FPS的能效TCO可以降低6倍;運(yùn)行BERT時(shí),每SPS的能效TCO可以降低10倍,可以有效地降低能耗。
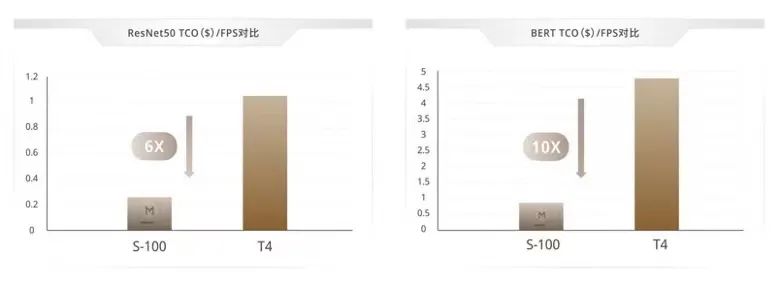
更進(jìn)一步,在面向業(yè)務(wù)的使用方面,由于客戶能夠便捷地使用墨芯的編譯器,同時(shí)稀疏化算法又具有通用性,在具體場景下,客戶往往只需要改幾行代碼,就能適配新的計(jì)算卡,完成優(yōu)化。
目前,墨芯的主要客戶面向數(shù)據(jù)中心AI推理應(yīng)用,在互聯(lián)網(wǎng)、運(yùn)營商、安防、生物制藥和FinTech等場景下已有了具體的實(shí)踐。
對于互聯(lián)網(wǎng)客戶來說,墨芯高性能芯片能夠幫助客戶提高內(nèi)容推薦精準(zhǔn)度、廣告投放精準(zhǔn)度。普通消費(fèi)者在日常生活中經(jīng)常需要AI芯片提供算力,高性能的芯片能夠讓社交媒體更懂你心、更精準(zhǔn)推薦;在線翻譯場景中,墨芯高性能芯片可以讓翻譯更實(shí)時(shí)更精準(zhǔn)。
在三年多的發(fā)展過程中,墨芯受到了產(chǎn)業(yè)資本和財(cái)務(wù)資本的共同助力。王維告訴「甲子光年」,“產(chǎn)業(yè)資本、財(cái)務(wù)資本的助力,幫助墨芯產(chǎn)品能更好地落地。但同時(shí),一家科技企業(yè),核心還是將技術(shù)創(chuàng)新轉(zhuǎn)化為生產(chǎn)力,水到自然渠成。” 王維相信,稀疏化計(jì)算將為墨芯帶來無限的發(fā)展空間和機(jī)遇。
本文來自微信公眾號 “甲子光年”(ID:jazzyear),作者:范文婧,36氪經(jīng)授權(quán)發(fā)布。


























