聊聊 BI 的黑武器 —— 分倉分庫、前置倉,大型集團 BI 數據架構規劃思路

大年三十除夕的清晨,迎接新年的最后一篇文章來講講大家平時可能很少接觸到的一類數據架構。
因為這種架構少有產品化的落地使用,市面上也沒有很好的參照。而我們在兩年前做我們自己 BI 產品的時候就已經把這個概念給產品化了,所以我們把這種架構就取了一個名字叫做 BI 的分倉分庫、前置倉。
講這個架構之前,我先來講講幾個失敗的案例。具體案例名稱就不在這里提了,就說下這幾個項目比較共性的需求背景。
共性的需求和場景
十四五規劃,數字化轉型大背景下,一個集團七八十家公司二級單位,二級以下還有三級、四級。集團要求做所謂的數據中臺、大數據 BI,總之最后的要求大概就是做到:拉通數據、一企一屏、集團財務業務一體化的可視化分析,實現資產監管等等。
聽上去是不是感覺很熟悉,就像身邊的企業集團一樣?非常正常,太多類似于這樣的需求了。我面對面聊過的這類需求已經不下十家,聽到的就更多。
這些案例大概是什么需求背景呢 ?首先要做的就是財務監管方面的各個系統打通。以往是通過數據報送看看基本的報表就可以了,現在要求所有二級財務系統要對接到集團層面,能夠看到更詳細的、深入的數據分析,這個是一期的規劃。二期就是從業務線、業務板塊按照同樣的方式,所有的業務數據都上來,逐步實現一企一屏、集團管控、集團大屏等等,實現集團視角、業務板塊視角、企業視角等可視化分析。
最終的輸出大家注意到了嗎,都是什么? 都是 BI 可視化分析、大屏可視化,所以 BI 在這些項目里面是一個剛需。難的地方在哪里?在底層數據上,不僅僅是數據清洗、治理,更重要的是數據架構到底應該怎么來構建才更加高效。
第一家是怎么做的呢?底層上了一個大數據架構平臺,對外叫數據中臺,把所有的二級企業集團的數據全部同步到集團的云端,然后在云端做數據的清洗、合并等等一系列 ETL 加工處理,最后通過 BI 工具做可視化分析。這個實現思路是對的,難就難在只考慮到了數據搬過來上云,忽略掉了數據處理的復雜度。上百家企業的數據如何合并,如何抽象出共性指標,如何打通這些數據。這個項目最終也沒有跑起來,死在抽取之后數據加工到出 BI 這個層面,一家企業數據出問題,最后的大數就是有問題,死活不知道問題出現在哪里。
直接把所有數據拿過來放到一個平臺,在一個大平臺里面做清洗處理,組織架構、維度科目檔案統一如何做,指標口徑如何統一?一個點出問題處處都是問題。
這個是思路對了,實現難度大,沒有考慮到這種復雜性,沒有針對性的找到復雜場景下的解決措施。
而下面這個是思路就不對,錯得離譜。
第二家的做法是直接在業務系統中對接各個集團財務系統的數據,然后在這個業務系統中做合并,最后作為大的數據出口、數據源為未來集團 BI 所使用。這種架構就是從方向、從根上完全錯了,心思就不正。說嚴重一點,就是很壞。這樣一做,基本上就把甲方給完全綁定了,以后說是什么就是什么。即使財務數據相對標準,集中到一個業務平臺上,其他的業務數據以后要分析怎么辦?
其他看到的幾家項目做法介入這兩者之間,處理方式和手段基本上就這些。
面臨的挑戰
這幾家面對同樣的問題主要是:
第一,各個二級企業(集團) 所用的財務系統各不相同,有用友NC、用友U8、金蝶 EAS、浪潮、還有用友 T 系列的。很多人問為什么當初集團不統一這些系統,大家需要知道一個大型集團的成長都是靠兼并、收購、重組不斷的進化的,IT 信息化不統一非常的正常,IT 信息化建設很難提前規劃和預判。
第二,各個企業由于自身的業務特點,各個業務系統也不一樣,非統建類的系統居多。
第三,即使是同業務板塊的下屬二級企業,有的企業有相應的業務系統,有的企業就沒有相關的業務系統支撐。
這里面的共性挑戰是什么?
第一,不同的系統由不同的供應商維護,底層數據字典、數據質量的問題,這么多業務系統要取數,有的還做過二開,數據怎么取的問題,誰來配合解讀數據。
第二,集團到底要看什么數據?知道這些數據從哪里取嗎?什么時候取哪些數據?七八十家企業,幾百個系統,等你整合完,報表什么時候才能出來?
第一家的實現思路沒有太大的問題,但是第二家的實現思路實在是不可救藥 —— 讓各家業務系統供應商提供標準 API 接口,從各個業務系統 API 接口取數全部集中到自身的業務平臺中。這里面涉及到多少家供應商資源的協調,需要多少的二次 API 開發工作投入。并且最嚴重的一個問題是,業務系統不是數據系統、BI 系統,業務系統彼此之間應該是完全獨立的,只有數據系統、BI 系統才能完全基于所有業務系統之上,形成各業務系統數據的打通、建模再到支撐 BI 前端可視化。
所以,這家架構從根上就錯了,項目已經啟動半年一直無法推進,我上會溝通了一下發現已經無法扭轉了,救都救不回來。
集團型 BI 的數據架構實現思路
像這類項目實現思路到底是什么?有沒有一些優化的方案或者架構可以供參考借鑒的,這就是我下面接著要說的幾個點:
第一,不管是什么樣的財務監管、一企一屏、集團 BI 可視化,最終大家都需要注意到,BI 都是最終的出口,這個是最終使用用戶唯一能看懂的東西。
第二,一定不會先上來把上百家二級企業的業務系統數據先打通一遍,做整體的數據建模,一定不能這么干。
有的人說我們集團要求業務上云、數據上云,所以數據全部要搬過來。注意,搬過來和打通是兩回事,搬過來只是數據到集團的云端了,打通是真正意義上數據的打通、清洗、匯總、合并等一系列的處理。這種打通,不要說上百個系統,就一兩個系統的完整打通,按照 BI 建模的方式走一遍基本上就是幾個月甚至小半年時間。
第三,一定從需求出發,先梳理分析指標,需要什么指標就看什么指標。不管是財務的,還是業務的,確認多少,再抽取多少,這樣可以不用在最初的時候把面鋪的過大。舉個例子,全部系統打通可能涉及到上百個系統,這個工作量太大。
但是這次梳理出來的一部分指標,可能只涉及到幾個系統的打通,階段性的工作量一下子就降下來了,難度也就下來了。
把這三個點弄明白,我再來講講下面的這種架構就容易很多了。
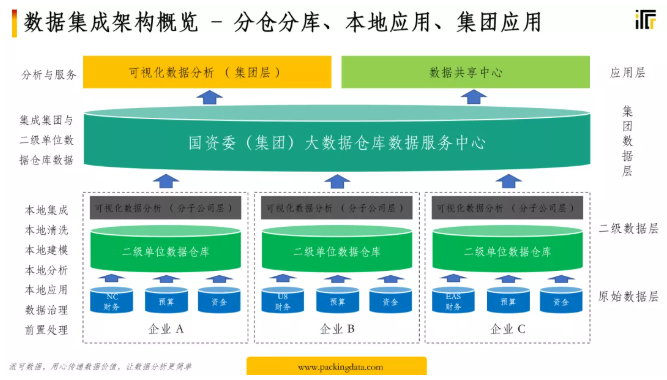
第一,明確集團層面需要看什么數據,看什么數據就抽取什么數據。這種要看的數據從 BI 的視角來說,就是指標和維度,所謂的明細數據就是維度的顆粒度,維度顆粒度越細,數據明細就越細致,定好了就可以了。
第二,既然是集團層面的統一視角,所以這種數據的模板或者格式就是高度統一的,適用于所有的企業。
因此在某一個階段,二級企業數據到達集團大數據倉庫中心之前,因為已經知道了需要獲取什么樣的數據,所以在二級企業設置前置數據倉庫。按照規定的數據格式、模板同步到二級企業的數據倉庫中,二級企業的數據清洗過程不是放到集團數據倉庫層面,而是在二級企業的數據倉庫中完成。
這個就是 BI 數據倉庫的分倉分庫,前置數據倉庫的概念。
這個前置數據倉庫服務器可以放到二級企業本地,也可以放到集團統一管理。位置在哪里并不重要,重要的是要降低數據邏輯處理的并發復雜度。
什么叫并發復雜度?比如我有一個大屋子,大屋子里有十個房間,每個房間放了好多雜亂無章的東西,現在要把東西給清理出來拉到大屋子的大廳擺放整齊。
兩種處理方式,看看哪種更好:
第一種,直接把每個房間的東西全部拉到大廳里面,然后再分門別類的整理。
第二種,在每個房間整理好,然后再拉出來放到大廳擺放。
大廳就是集團的數據倉庫,在房間整理好就是前置數據倉庫,明顯這種方式更優。全部拉到大廳再來整理,容易手忙腳亂,互相打擾,一個錯誤全部就亂。
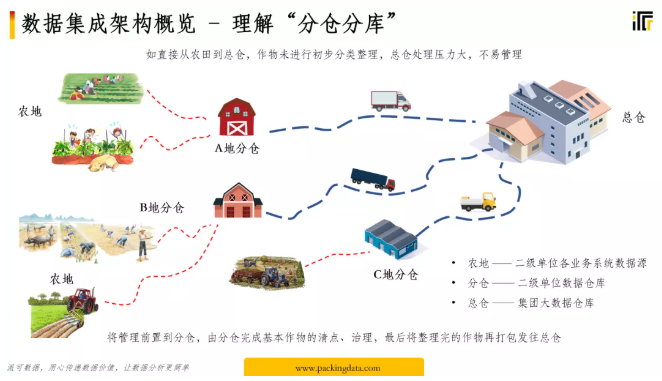
就如同上面的這幅圖,各二級企業的數據就像各個農地里面的菜一樣,就地分倉處理,處理干凈了再合并到總倉中,這種效率非常高。
比如一家集團上百家二級使用的財務系統各不相同,沒有分倉分庫的話就需要一家一家的進行數據對接。有數據倉庫模板的話就相當于各個版本的財務系統只需要對接一次,剩余的直接按照模板復制到各地數據倉庫就可以了,七個財務系統版本就對接七次就可以做到。
數據倉庫的模板是什么?分析模型、維度、指標、以及維度指標的取數邏輯,這些都可以有效的組織和統一模板,高度復用。
上面的這些架構,我們很早就已經落地了,并且是以產品化數據倉庫的形式落地。
場景越復雜、分倉分庫、前置倉架構的優勢越大
這種架構使用的場景非常的多,集團越大越適合,業務系統版本越多越適合,足夠大,高度可復用的效率優勢體現的會更加明顯。
這種架構具備很強的擴展性和想象力,比如像國資委的國資監管、大型集團的多級 BI 架構、甚至只要有這種帶有上下級數據傳遞整合打通,不管多少級都可以按照這種架構思想來實現,可以把每個分倉無限往下擴展成不同的小倉庫,從小倉到大倉,從大倉到總倉。
數據架構這些東西沒有什么可神秘的,就像一層窗戶紙,一捅就破,關鍵是在不同的項目中要靈活運用。
本文經授權轉載自微信公眾號 呂品聊數據 作者 呂品



























