登錄


基本概括
定價
免費試用
不支持
不支持
定制
不支持
不支持
價格套餐
-
獲取獨家報價
-
獲取獨家報價
客戶規模
小型企業
(50人及以下)
-
26%
中型企業
(51-1000人)
-
42%
大型企業
(1000人以上)
-
32%
評分
綜合評分
暫無評分

2.2
分


易用性
暫無評分
4.8
分
穩定性
暫無評分
暫無評分
售后服務
暫無評分
4.0
分
點評

將此報告發送至我的郵箱
發至郵箱
問答
熱門問答
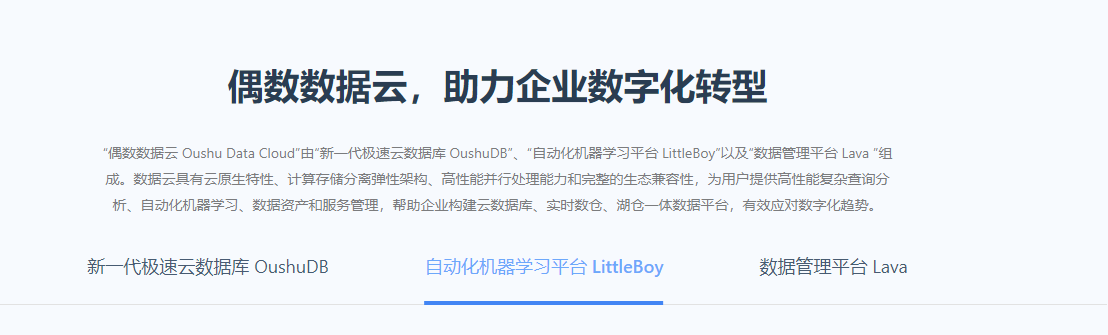
產品截圖
截圖對比
1/3
1/4











消息通知
咨詢入駐

商務合作
