圖行業的一些觀察:以圖數據庫為例|NUC 2022

本次分享的內容本來是圖行業發展及標準的深度解讀,這其實是個很大的話題,所以我把標題換成了一個小一點的標題。因為我覺得整個圖行業它其實是一個非常大的行業。每個人在里面其實只是在盲人摸象,我可能只是摸過大腿而已,其他部分我也沒有摸過。說不上做一個深度的解讀,只是說我在這個行業的一些觀察,因為我覺得我只摸過四條大腿的其中一條,所以又加一個副標題,以圖數據庫為例。
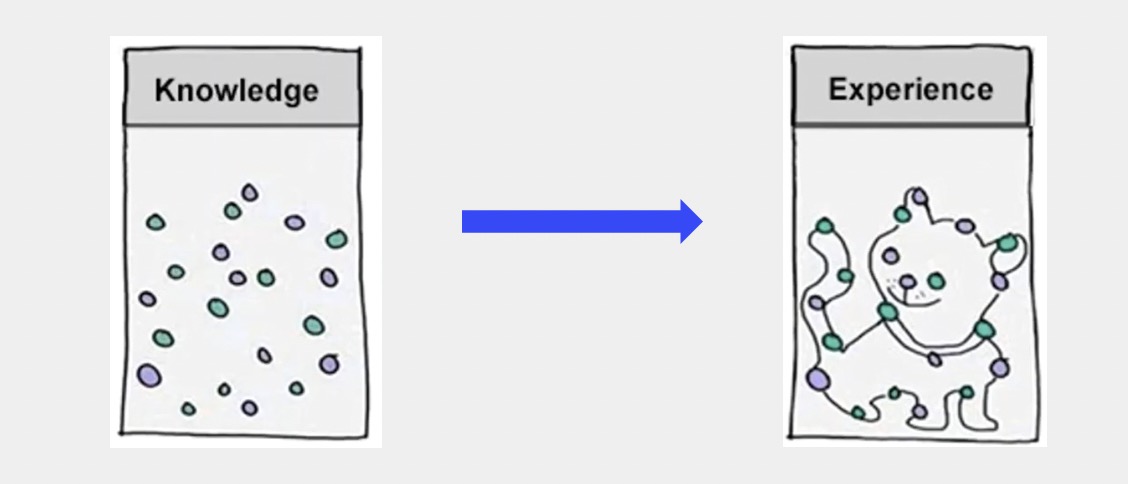
圖的思想,哪怕這個術語出現的很晚,但是人類早就已經有這個概念了,或者早就已經有這個認知了。就是大家會發現其實光有這些零散的知識是不夠的,需要把這些知識給關聯起來,關聯之后才能變成指導我們日常生活的經驗。所以一個概念很早的時候就已經有了:"關聯"是很重要的。
我剛才說圖這個領域是非常非常的大,在 2020 年的時候,有一家公司GraphAware,他曾經嘗試想把整個圖領域里面的一些公司或者產品給列舉一下,這其實是很難的,因為實在太多了。他大概做了一個分類,有基礎設施的、應用的、開發者工具的,還有一些會議之類的。比如說在20年的時候,當時有NebulaGraph、GQL、DGL了,這些都是我們今天可以聽到的。其實想把整個圖完全整理出來是挺難的,我稍微做了一點點總結和濃縮。在圖領域的話,大概有四個大的部分:基礎設施、開發者工具、應用和信息資源。

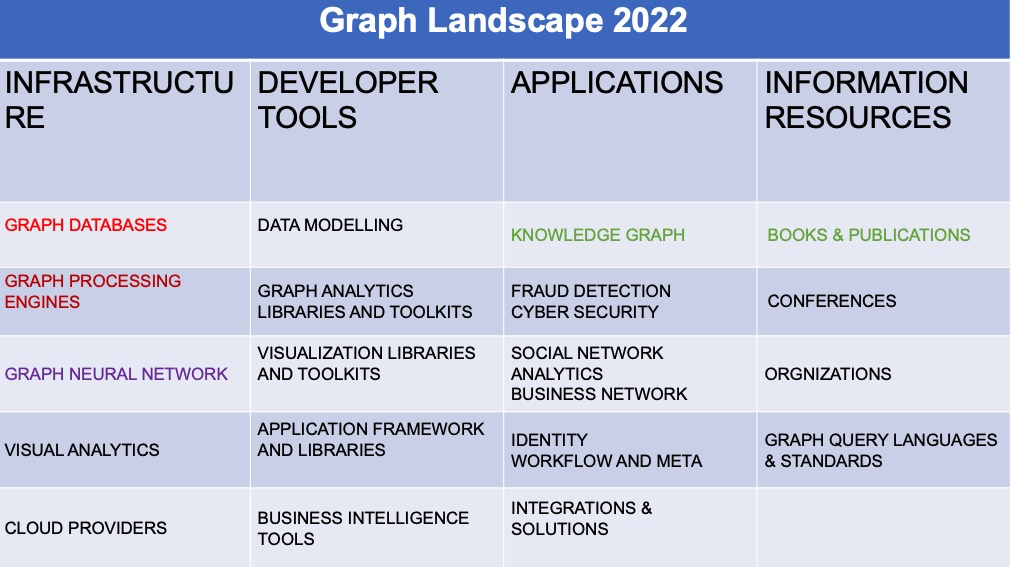
像基礎設施的部分,比如說今天我們要談的 Graph Database,還有一些可能會涉及到圖 Processing 和 Computing 的系統。然后像圖神經網絡、可視化分析和云服務商,這些基本可以分類為整個圖領域的基礎設施部分,他們是基礎設施的提供商。
然后接下來說開發者工具,一般主要是建模的工具,圖分析和可視化的函數庫、工具或者 SDK,還有一些 BI 場景的工具。當然還有其他的一些開發者工具,就不一一列舉了。
還有應用領域,比如說圖譜。圖譜本身是一個很大的領域,圖只是為圖譜提供一些基礎設施的服務。還有一些常見的,比如說欺詐檢測、網絡安全,或者是社交網絡、商業網絡的圖。這些是圖比較常見的一些應用領域。
還有一些是圖領域的信息資源。比如會議、書籍、論文。九月份的時候,VLDB 的 Research Session,大概有 1/5 都是和圖相關的;還有今天我們的 NUC,這也是圖領域的一個會議。還有一些國際化的組織,比如說像國際化的 ISO、IEC,他們在為國際標準做一些努力。還有一些民間的組織或者第三方的組織,比如說 LDBC,可以為這個領域的發展做一些貢獻。這些挺好地反映了圖行業現在的成熟程度。
圖這個話題還是挺大的,所以先看一點簡單的歷史。可能大家都聽說過七橋問題,或者是西爾威斯特提出的矩陣和圖論這兩個名詞,這都是歷史上的概念,不是我們計算機學科要談的。
1960-1980s: 數據模型與數據系統的定義
計算機系統里面的圖,有這么一個歷史,在 60-80 年代的時候,其實大家的主要工作都是著重在圖模型和數據系統該怎么定義上面。最早我能查到的是巴赫曼,1960 年的時候,當時他在 GE 的開關電器廠工作,發明了 IDS 系統。這個系統對后世所有的數據管理系統都有很大的影響。巴赫曼應該是最早的先驅,當時他所采用的模型后面被稱為稱為 Network Model 或者 Network Data Model。它本身的特點是把記錄 record 通過Linkage 關聯起來。比如上面這個例子,一個記錄可以和很多其他的記錄相互關聯。這應該是在計算機系統里面最早實現的一個圖模型系統。當然后來巴赫曼獲得了圖靈獎。

60年代的時候,大家重點工作是放在圖或者網絡模型上面。到70年代的時候,最著名的成果就是科德發明的關系模型了。從關系模型到關系代數,一路演變成了RDBMS的這一整套技術。科德在70年代發明的關系模型相比60年代的網絡模型,他認為自己的進步在哪里:就是60年代的網絡模型,或者說那個時候的圖系統,只能夠處理一系列確定主鍵的記錄之間的關聯;而他所發明的這個Relational Model,他可以對任意的值進行匹配。如果用數據庫的話,就是value-based join。這樣整個模型會更加地通用。因此在后來很長的一段時間,可能有三四十年的歷史里面,RDBMS基本上主導了整個數據處理市場。
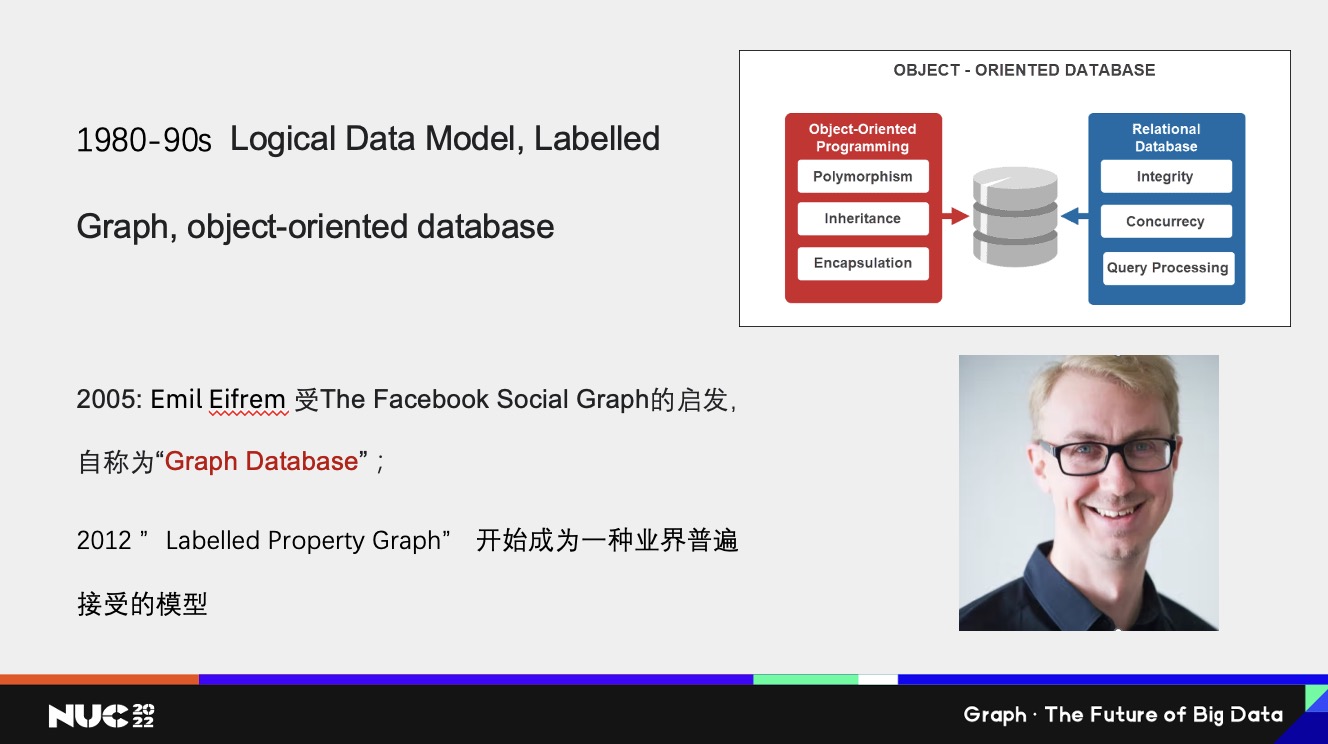
整個圖相關的模型還在繼續往前走,比如說到 80-90 年代的時候,有了Logical Data Model。再比如說標簽圖或者標簽網絡,這也是現在我們常用的 LPG(labelled property graph)概念中的一部分。因為 90 年代的時候面向對象很流行,也有人嘗試想把面向對象的這個概念引入到數據庫系統里面,比如說數據庫原來已經有這些ACID的功能,嘗試想把這種多態、繼承或者封裝功能引入到數據庫系統里面。當然,其實多態或者繼承本身也是帶一定的圖關系的,當然今天看有些探索并不是成功,但也是往前的一些進步。
大約在05年的時候,后來的 Neo4j 首席執行官 Emil Eifrem 聽說在哈佛有個軟件挺流行的,叫 The Facebook Social Graph,然后他覺得自己正在做的一個媒體管理軟件也是一個 Graph 結構。他當時在飛機上,突然就靈光一閃,自創了一個新的名詞 Graph Database。這應該是我能查到的這個單詞(Graph Database)最早的起源了,后來這個名詞也是過了很久才慢慢為大家所知。
到12年的時候工業界大部分采用的是 Labelled Property Graph模型。相比基本的網絡模型做了一些擴充,比如說 label 加上了,把 property 加上了,這個概念到今天為止也是在圖數據庫這個領域里面比較常見的模型之一。另外一個比較常見的模型就是 W3C 為 RDF 所做的這一套定義。這兩種模型到目前為止還是比較常見的。
整個數據模型還在繼續向前進步,大約到18年左右的時候,嘗試為圖或者網絡的模型添加 streaming 或者 temporal 的時序能力。相關工作還在繼續開展,也有一些論文再發布,能看到一些相關產品。
2010s: 圖數據庫與圖計算系統的相互促進
剛才提到的這些模型,可能是很久之前的歷史了。大約在2010年前后開始,在圖這個模型里面,出現了兩個比較重要的分支,圖數據庫系統和圖計算系統。這兩個分支先是獨立發展,之后是相互促進。雖然數據模型是一步步演進過來的,但是圖數據庫和圖計算系統兩種系統最初是各自獨立發展的。
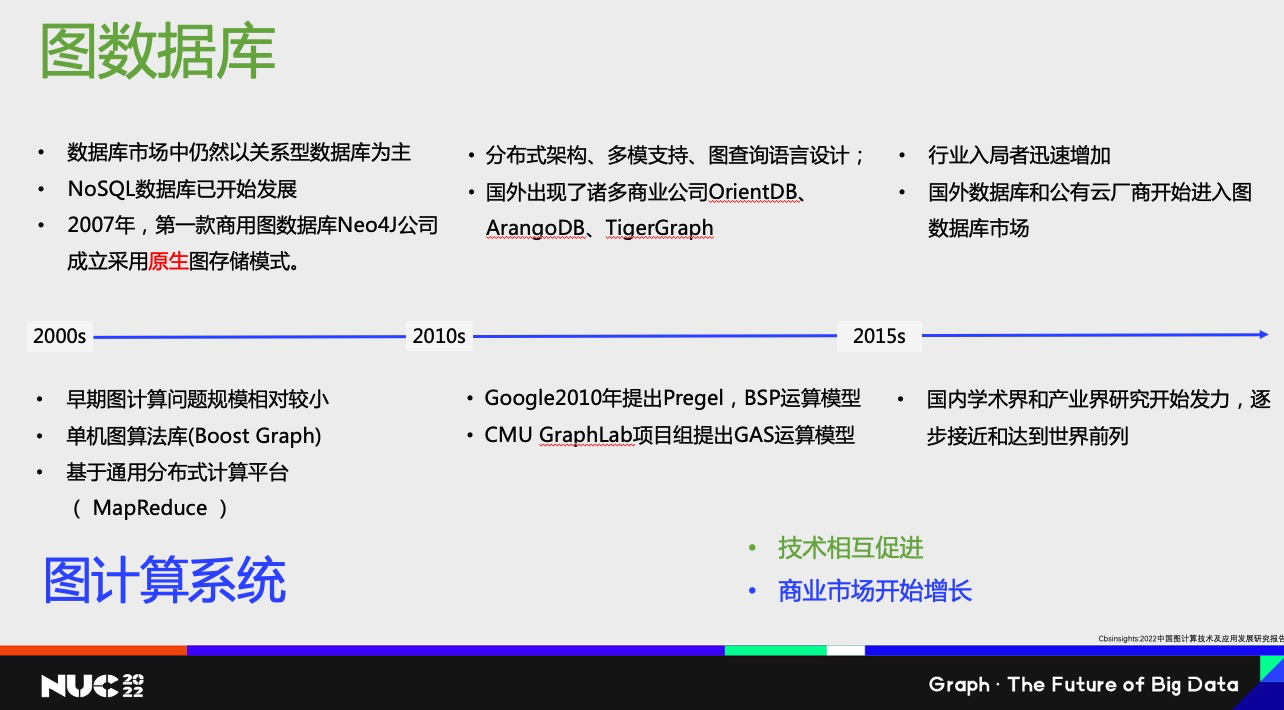
圖數據庫系統基本上和數據庫系統的關系會更大一點。在 2000 年到2010 年之間,圖數據庫系統基本上還是 NoSQL 系統中的一種嘗試。他們面對的還是想解決 RDBMS 中有些不好解決的一些小的細分領域問題。
而圖計算系統,它當時能解決的都是一些小規模的圖。比如單機處理一個圖計算的場景,或者是使用 Boost 里面的 Graph Library,或者MapReduce 來非常原始的方式來實現圖計算。
從大概10年開始,兩種系統都得到比較大的發展。圖數據庫對于分布式架構、多模支持和圖查詢語言設計這些方面都開始進入技術成熟階段,也出現了很多新的商業公司開始進入這個領域。對于圖計算系統來說,出現了兩個比較重要的計算模型,BSP 模型和 GAS 模型,這兩個模型使得大規模并行地分布式圖計算變得可能。當然也產生了一系列圖計算和分析為主要目的商業公司。
這兩種系統在 15 年前后,技術開始相互促進和融合。商業公司會相互借鑒對方的技術,把對方技術引入自己的產品里,然后去服務更多的場景。在 15 年前后行業的入局者開始迅速地增加。不光光是國外,國內也出現了更多的公司。原有的數據庫公司和云廠商也開始進入這個領域。國內的學術機構和產業界也有比較明顯的進步。已經可以逐步接近和達到世界的前列。所以對 15 年之后的總結就是技術上相互促進,商業市場已經開始增長。
2018- Graph + AI 的快速興起
然后在 18 年前后,在技術上又發生了一些變化。Graph+AI 的領域開始快速興起,這里的 AI 比如說像連結主義為主的神經網絡,或者是符號主義為主的 Knowledge Graph。
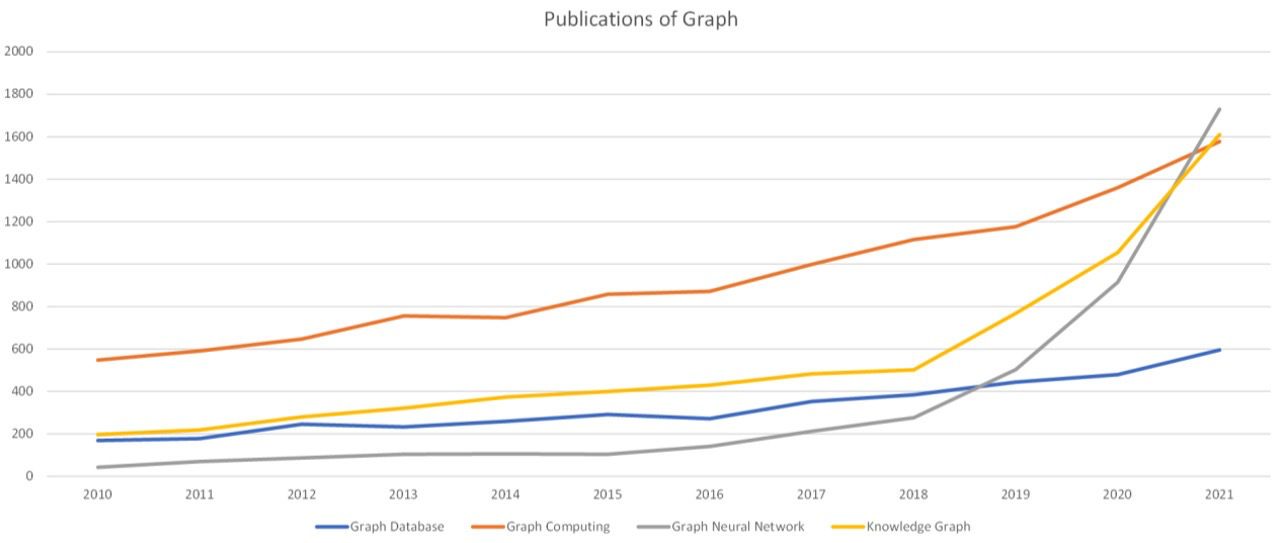
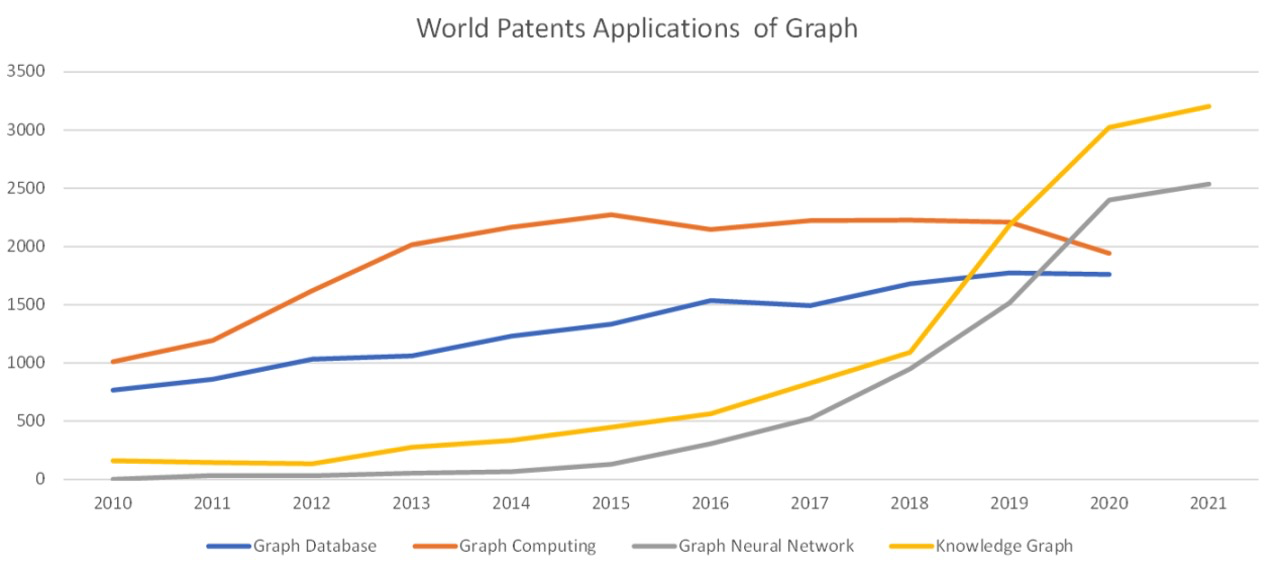
Graph和AI的結合使得這個領域出現了很多新的研究。有幾個例子,一個是我從Web of Science拉了一下論文的情況。大約從10年到15年左右,Graph Database、Graph Computing、Graph Neural Network和Knowledge Graph總體來說都保持了一個相對平穩的增長,但是到18年左右,和 AI 相關的 Graph 的論文數量就發生了明顯的提升,這說明了學術界研究熱點的變化。還有一個是專利的情況,這是我從 WIPO 拉取的和 Graph 相關的專利申請情況。在前期的時候,Graph Database 和Graph Computing 的專利申請會明顯多一些。然后到18年左右開始的時候,和AI相關的Graph Neural Network和Knowledge Graph專利申請有明顯的提升,這說明了工業界的變化。一般來說,工業界會更關注專利一些,學術界會更關注論文一些。可以說Graph+AI在最近這幾年都得到極大的發展,不管是在學術界還是工業界。
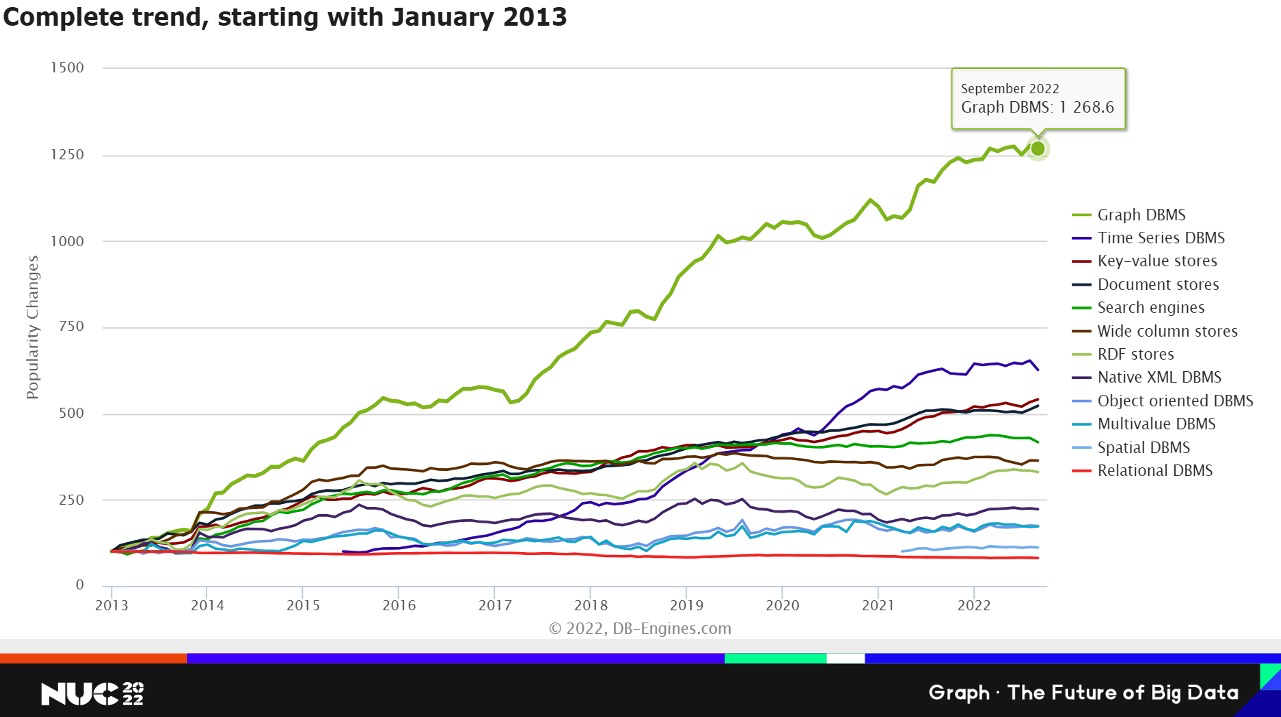
因為我們想談的是 Graph Database,所以從 Database 領域來簡單看一下。在 Database 領域有很多的分支,DB-engines 網站會對不同的分支品類統計流行情況,反應流行度的增長趨勢。比如說 Relational DBMS(下面這個紅色的曲線),他的基數已經很大,增長趨勢不會很大。但是對于 Graph DBMS 來說,這么多年以來,都是增速最快的分支。所以從Database這個角度來看,Graph 領域也是增速最快的。
2013-2022:Hyper Cycle of Graph Databases
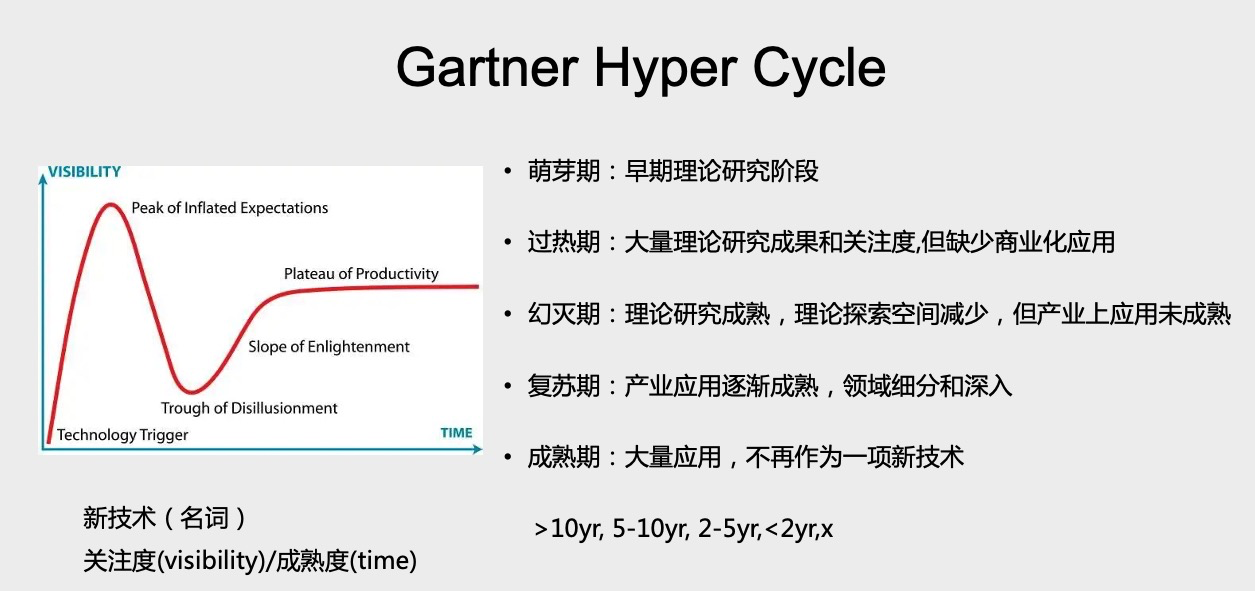
然后我還去找了一些研報或者三方研究機構對這個領域的一些看法。其中最著名的就是Gartner。Gartner從13年開始,每年都會去研究Graph這種領域的進展。它有一個非常著名的 Gartner Hyper Cycle 曲線。簡單說一下,Gartner 認為一個技術會有兩個 Cycle。第一個 Cycle 是從萌芽期進入過熱期再進入幻滅期,這期間會有大量的智力和資本進入這個領域。然后第二個 Cycle 是從復蘇期進入成熟期,這個技術成為整個商業日常運營的一部分,不再作為一個新的技術名詞出現。
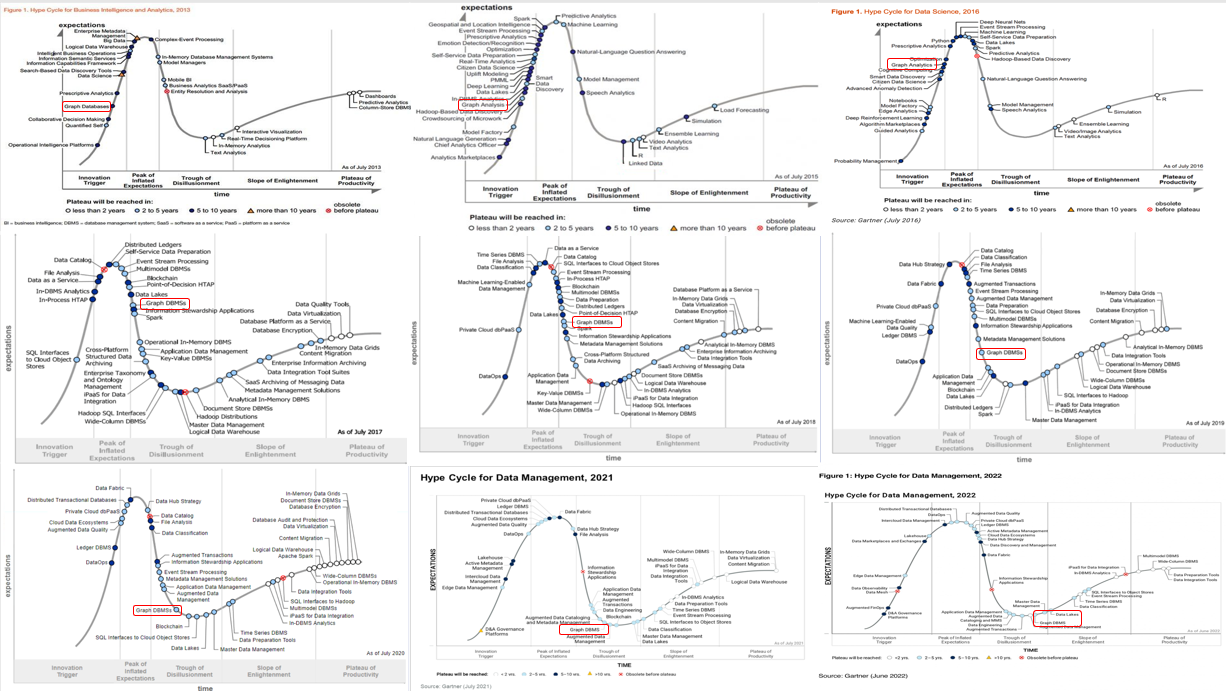
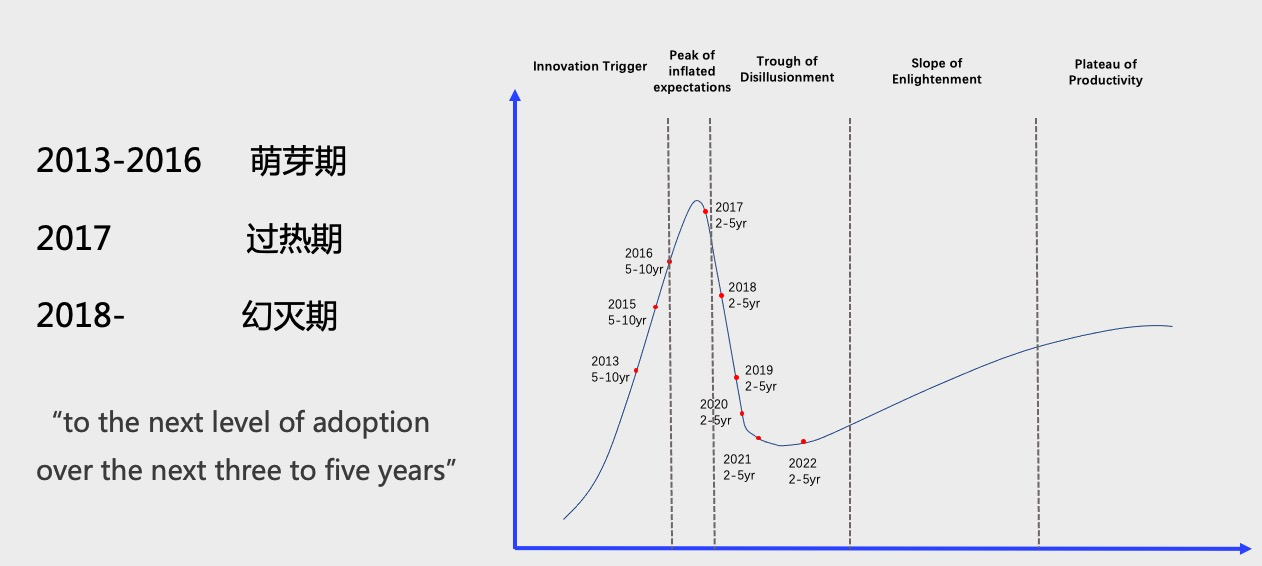
Gartner 對于 Graph DBMS 從 2013 年開始一直有跟蹤,我把它稍微重新整理了一下。在Gartner看來,整個Graph領域的情況是這樣子的。大約從13年到16年,這是第一個Hyper Cycle的萌芽期,大家在嘗試探索說哪些領域或者哪些新的技術可以被引入和使用。在17年左右的時候,這是第一個 Cycle 的高峰,之后的三年時間,進入第一個Cycle的幻滅期。從21年到22年開始進入第二個Cycle的爬升期。根據Gartner的預測,他認為在未來的3-5年內,Graph Database 這個領域會進入一個技術的成熟期。
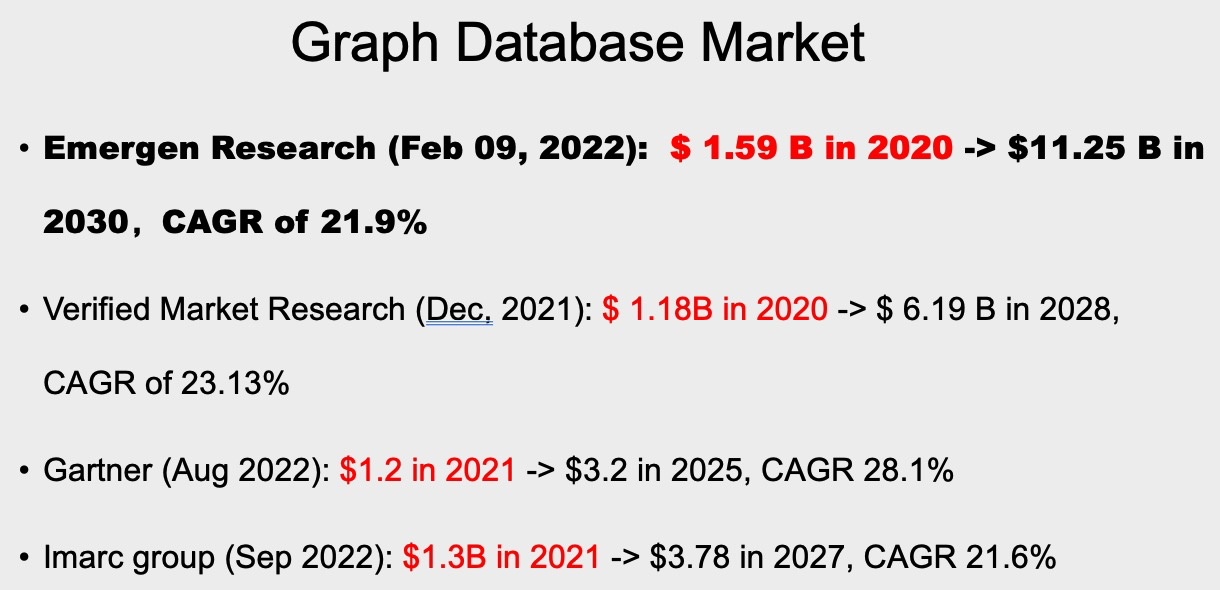
對于整個 Graph Database 的市場營收情況的一些預計,不同的研究機構給出的研報可能不太一樣。但是大體上數據都是最近20 21這兩年有十幾億美元的營收,并且大約保持 20%+ 的年復合增長率。這個增速大概我看了一下,略高于一點點 RDBMS 市場的增速。當然這是一個全球的情況,那如果看國內的情況,獨立的研報比較少,但從我們內部拿到的數據和幾家證券公司給的研報來看,國內的數據應該比國際數據的增速至少高一倍以上,內部能看到數據都是 50%~100%。所以國內會更樂觀一些,大概可能的原因還是國內相對基數更小,導入和起步也更晚一點。

最后一個部分是對未來做一些預測,當然預測還是很難的,所以我把它改一個名詞,叫做猜想。猜想分為三個部分,一個技術部分,一個產品部分,還有一個產業部分。
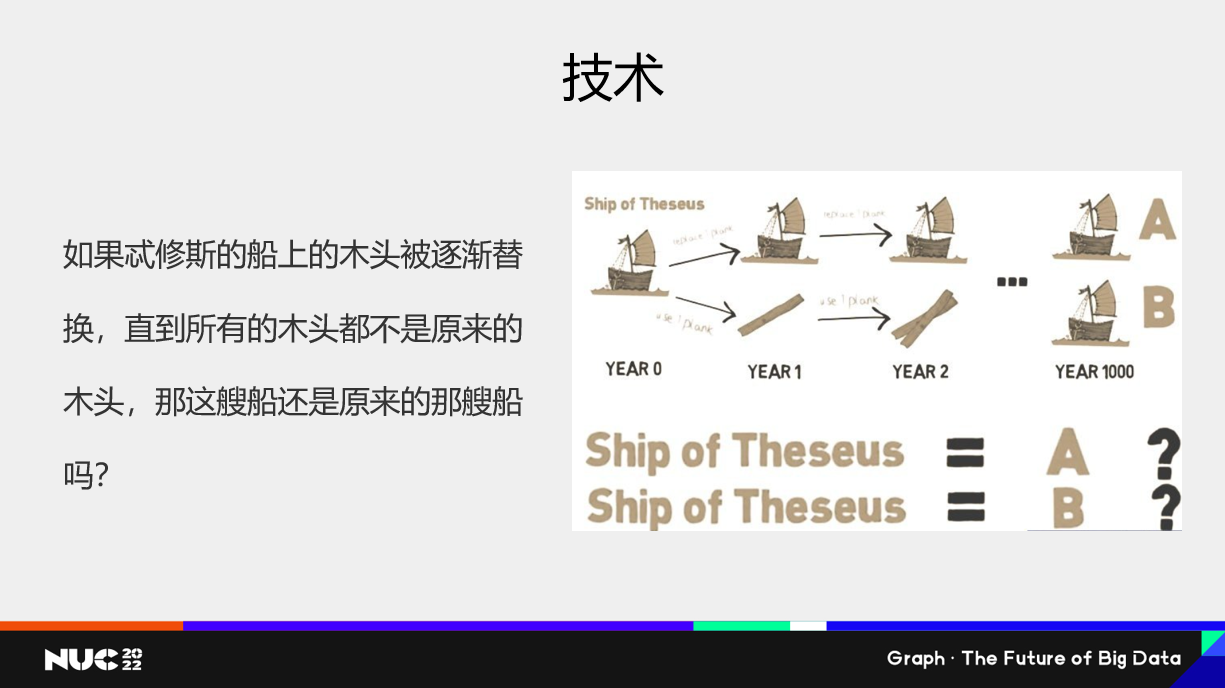
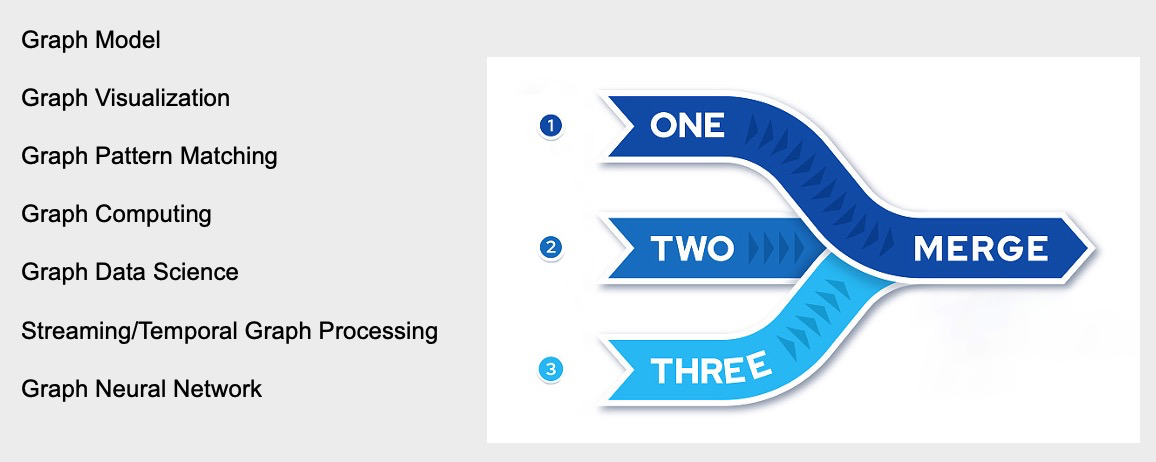
關于技術部分,Graph Database 這個名詞本身其實已經出現快20年了。然后我想引用一個隱喻:一艘船它的木頭逐漸被全部替代了之后,木頭還是不是原來的木頭,船還是不是原來的船?我想說就是 Graph Database從最初只是一個Graph Model 外加 Graph Visualization 的一個數據存儲系統,到后面逐步增加圖語言 Pattern Matching 能力、大規模的 Computing 能力,以及對于業務人員用的 Data Science 能力,加上時序、Neural Network 這些能力。是不是可以考慮為它創造一個新的技術名詞了。
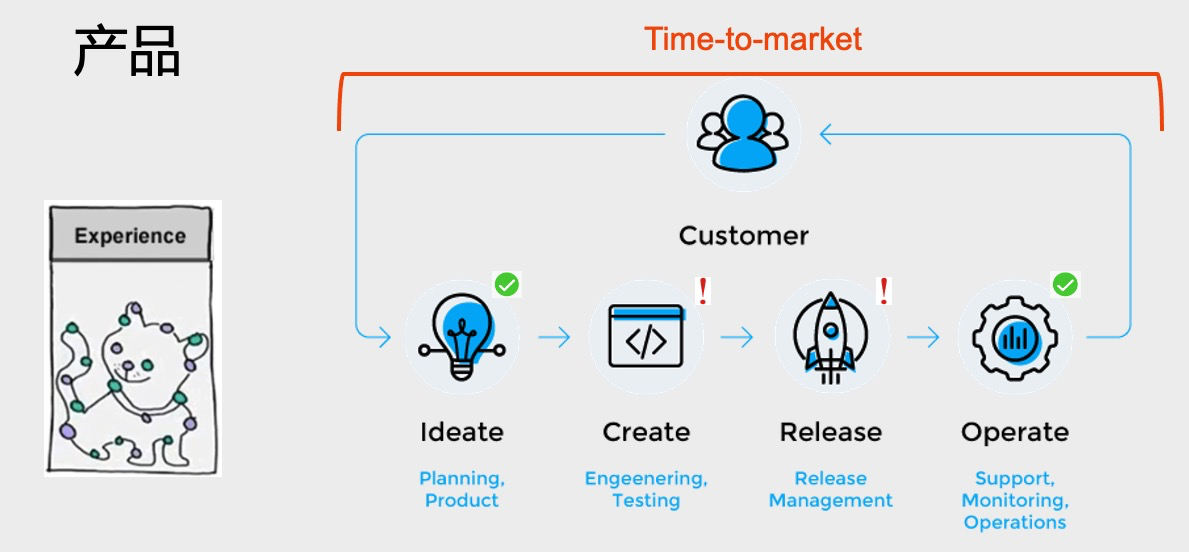
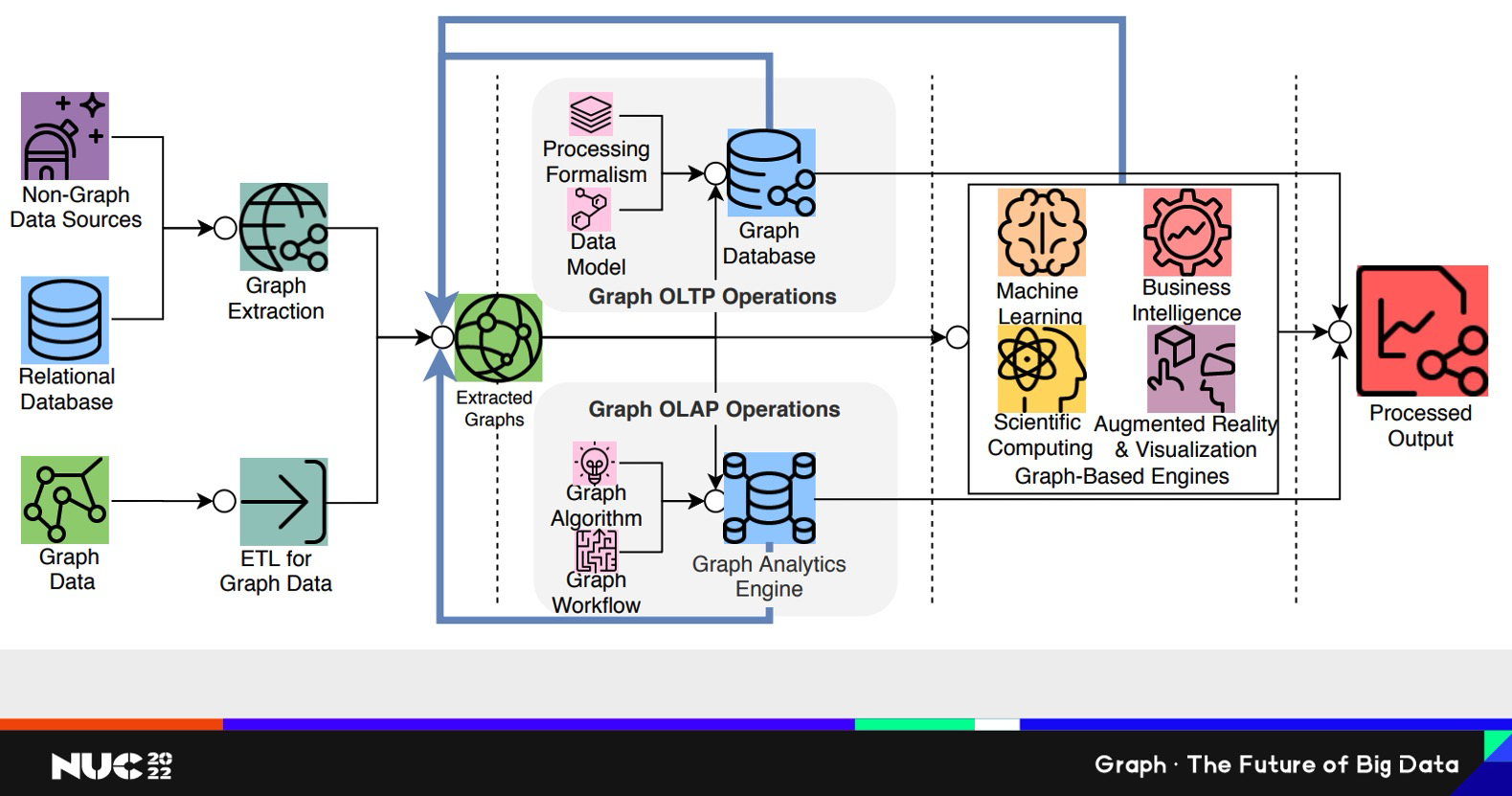
第二個是產品部分。關于Graph領域我覺得有一些問題。最前面說到要把知識串聯起來才能變成經驗。對于任何一個技術來說,都有這么一個Time to Market的過程。先有一個想法idea,然后要試一試這個想法行不行。如果這個想法行,再把它變成一個生產的部署,最后再進行運維;如果不行,我可以再返回再來一個循環。這整個過程Time-to-market其實速度是最重要的。其實Graph領域來說,它在idea這個階段是最適合的,因為即使業務人員不懂技術,對他來說也是很容易理解的,所以可以非常快的產生一個新想法。但是Graph領域目前的問題是在Create到 Release這個階段速度太慢。具體來說為什么速度太慢,就是整個Graph領域的技術對于用戶暴露的細節還是太多。不管是從OLTP的這個角度(上面),比如整個數據流的流程很長,加工完數據(ETL)要反饋到前面。對于OLAP這種分析為目的流程,也一樣有個抄長的流程。在這樣的整個流程里面,任何一個環節即使技術上極大進步,進步1倍或者10倍,但對于整個流程,特別是對于整個Time to Market的流程,其實可能只提升了5%。
另外一個問題是人員,因為如果對于一些小型的公司來說,他需要有數據科學家,要有DBA,要有業務人員,對他們來說可能人力成本就太大。每個人那么多細節要學習,對于公司決策者來說就很不經濟。這兩個階段的劣勢就抵消了Idea這個階段的優勢。
所以我的期望是說會有一些集成度更好的、對用戶更友好的產品。不管這些商業分析的用戶,他想用哪種數據模型、想要哪些算法,產品可以更好的提取出來,把這些復雜度包裝在后面,減輕用戶的心智負擔,讓用戶更快地去發現他所需要的商業價值,而不是把大量的精力都花在搭建一套甚至幾套很復雜的圖系統上面——這種事情只有大廠或者大型項目才做得到。技術目的應該是發現商業的價值。而這樣一個復雜的流程降低了整個圖技術在全市場普及的門檻。

然后是關于標準化部分。標準化其實和整個行業是有些重大影響的,比如ISO-GQL其實是一個很好的事,因為這對于所有的行業的使用者來說,它可以不再去學習每一個不同的vendor所提供的語言,當然是一件非常好的事。當然圖領域不只是一個語言,其實圖領域有很多的算法,除了大家常見的那幾個圖算法之外,還有大量的長尾的圖算法。而那些圖算法,每個vendor給的接口、給的數據導入的方式,它的工作流都是千奇百怪的。對于整個領域的開發者來說,他必須得為這些 vendor 去適配自己的系統,這也是一個很大的成本。還有就是關于整個行業的 Benchmark 的情況,這對于甲方或者應用來說是有意義的。但現在整個行業的 Benchmark 還是非常的少,只能體現產品在非常少的幾個場景下(比如社交、金融個別場景)的讀或者寫能力是個什么樣子。這對于甲方的決策來說還是不夠的,因為甲方需要有更貼近于他的業務場景的一些 Benchmark 供他參考。否則對于他來說,每個項目只能拉著 vendor 來一起設計 POC,對整個采購流程也有很大的阻礙,這里面就有很多商業運作的空間。所以我對于標準化的期望,就是能夠有更多的工作能夠使得整個行業的范式發生一個遷移。

最后一個部分是關于產業的,特別是關于中美市場。大家可以看到中美市場在第一個 Cycle 的時候,因為受益于理論部分的工作,兩個市場對于技術的接受程度比較一致。但在第二個 Cycle,就是技術成熟商業化階段,中美市場是不太一樣的。因為兩個市場的政治沖突,產業結構、市場化程度等等的差異性,會導致在第二個 Cycle 的時候,中美在整個圖領域會走上分叉,可能會走上導致不同的技術和商業化的可能性,而且目前看技術與商業都分叉的趨勢還是挺明顯的。

這個世界充滿不確定,最初開篇說到這里只是對于圖這個行業的一個小小的觀察和認識,所以希望上面這些內容能為大家提供更多的確定性,當然也有可能為大家提供了更多的不確定性。




















